Upgrade Openstack from Kilo to Mitaka
The upgrade of the openstack infrastructure based on Kilo wasn’t an easy task…we performed two releases jump and this process took several months because we had many goals to achieve, impacts that we had to care about both from an infrastructure point of view and from an application side: minimize the downtime for all running application and have a rollback path were (and they always MUST be) the core component!!

Other important elements that influence our upgrade strategy were:
- How our environment was built
- The amount of available resources
This definitively lead us to choose an in-place-upgrade.
Since the kilo release we had all services (I’m talking about the database, cinder, nova, ceilometer, rabbitmq)
inside controllers using Peacemaker/Corosync that provides High Availability for all, keeping them in a consistency state
due its constraints model.
However, resource constraints make difficult the management of some services because for example if
more than three or four openstack components depends from keystone, if I reboot keystone I automatically
reboot the entire chain!!
VIRTUALIZING COMPONENTS
So the first step was to re-design the current architecture thinking about the virtualization of
some components, starting from the galera cluster (with the classic three replica member), going
through the keystone service (and this was very important because it helped us to remove the core
constraints inside the Peacemaker cluster).
We also have virtualized the other openstack services such us the entire nova control plane,
ceilometer, the loadbalancers and horizon too.

GALERA CLUSTER
Focusing of some virtualized components, the first we need to talk is the Galera Cluster.
Previously we’ve had an instance of MariaDB on each controller using galera cluster to provide
replication between them.
In the new picture, this component has been virtualized and this allowed us to easily
mantain, monitor and troubleshoot each node without affecting in any way the controller nodes (in
which we have more other openstack services).
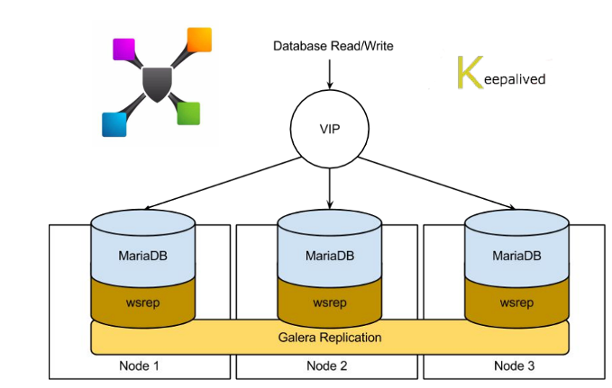
Of course it provides the classic replication model and allow us to be Peacemaker free, but from the other side we had to take care about all monitoring and alarming checks implementing them internally and then put them on the monitoring infrastructure.
VIRTUALIZED COMPONENTS: NOVA SERVICE
Talking about the nova service (actually the control plane), as we’ve done for the other services,
we’ve built two nodes in High Availability.
Up to here everything is very normal because we simply run two VMs (that in our future plans
could be containers) and put there the control plane, controlling the accesses through
the classic HA mechanism made by HAproxy and Keepalived.
What I need to evidence in this specific upgrade case is the Pinning of the compute RPC version:
in the first phase (Liberty) the nova RPC api were pinned to kilo because the whole control plane
of all services were in Mitaka except the nova control plane that remains in Liberty to allow
the live migration of the instances from the hypervisors running in Kilo to the hypervisors in
Liberty.
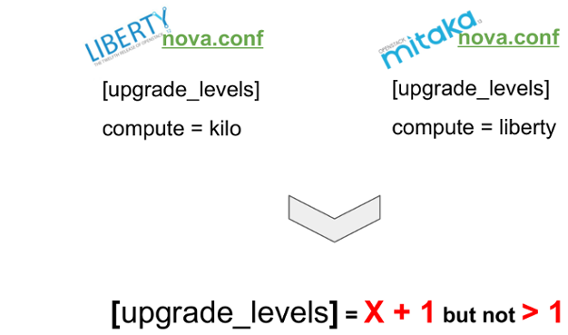
Of course this is really strange: the first idea was to make a one shot upgrade on all the control plane (going directly to Mitaka) and making a pinning to Kilo, but we found it’s not possible for two reasons:
- The nova conductor is able to understand only X +1 messages.
- From Kilo to Liberty the way to compute free RAM (and I think other resources) on the destination compute nodes has changed and this could let the live migration fail, forcing us to hard reboot the customers VMs (EPIC FAIL)
THE ANSIBLE WAY
We use ansible to perform operations inside our infrastructure: it is simple, with few piece of
code we can manage everything, from the host operating system to the openstack single roles, so we
have some GIT repositories for our projects containing some ansible to make things: we’ve a role
for nova service, for cinder, glance, neutron and so on.
This is very important to help us to keep aligned the infrastructure.
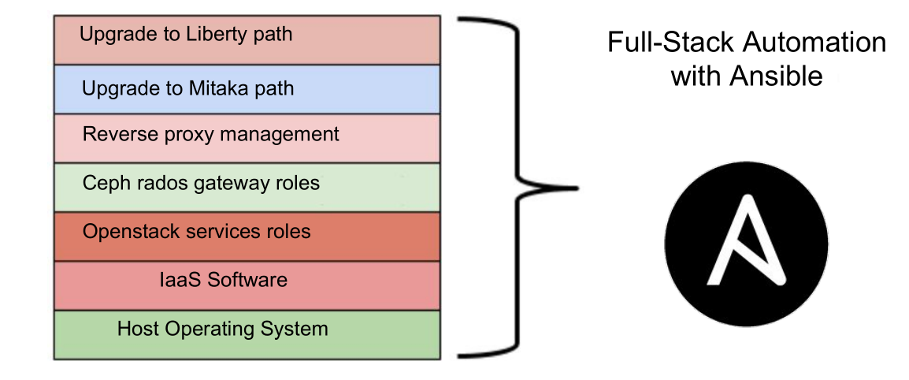
We have roles to configure the host operating systems, deploy nagios monitoring checks and customize with some specific external parameters to make a system openstack-ready depending to its role inside the infrastructure; To have more control to the upgrade we developed three main ansible playbooks:
- UPGRADE2LIBERTY
- UPGRADE2MITAKA
- FUNCTIONAL TESTS (with some defined roles defined for each component)
IT’S TIME TO UPGRADE: PLANNING
The upgrade path required some planning, as I said the main goal was to minimize
the downtime for the running applications and to do that we’ve modified the neutron control
plane to allow controllers to be rebooted without compromising the reachability of the tenants’ virtual machines.
And yes, the following picture depicts a list (more or less oredered) of steps to make the
upgrade.

-
Prepare all virtual environment (we prepared all the virtualized components directly on mitaka and then we’ve stolen the VIP from the controller nodes);
-
Make integration tests (verify that everything works correctly) and set pre-defined checkpoints;
- Add Neutron Auxiliary nodes and switch the routers (we’re going to talk about this in the next section);
- Upgrade all control plane packages for most services to Liberty;
- Align the Loadbalancer configuration to prepare the stealing of VIP on Mitaka (haproxy and keepalived);
- Verify that all services are up and running (side by side) and then run the upgrade of the control plane packages to Mitaka (after have copied the correct repolist on all the nodes);
And finally we’ve the most beautiful section/phase:
- Disable virtualized services on the Peacemaker;
- Rollback of all routers on the controllers now up to date;
- Execute the new set of integration tests;
Now, this is actually the first phase of the upgrade path, the last section related to the upgrade of the hypervisors was not very automatic/simple, because in an hybrid architecture in which we have some pieces in Mitaka, the nova control plane in Libery and the Hypervisors in Kilo live-migration presented some issues (the hangs of virtual machines, the kilo nova control plane executes some RAM checks in Mb while since Liberty everything is thought in GB), but for now try to fucus on the neutron section to explain what we’ve done:
NEURON AUX MODE: ADDING TWO NEW AGENTS
The picture shows our default neutron schema, from compute nodes to the controllers: inside controllers we can find the L3 agents and the other components of neutron (for example the API, dhcp and so on), so the neutron qrouters stay inside the controller nodes and our default config was to have N L3 HA agents equals to controllers’ number. To allow us to make some upgrades in the control plane in a wasy way we decided to add two auxiliary neutron nodes as additional L3 agents and …
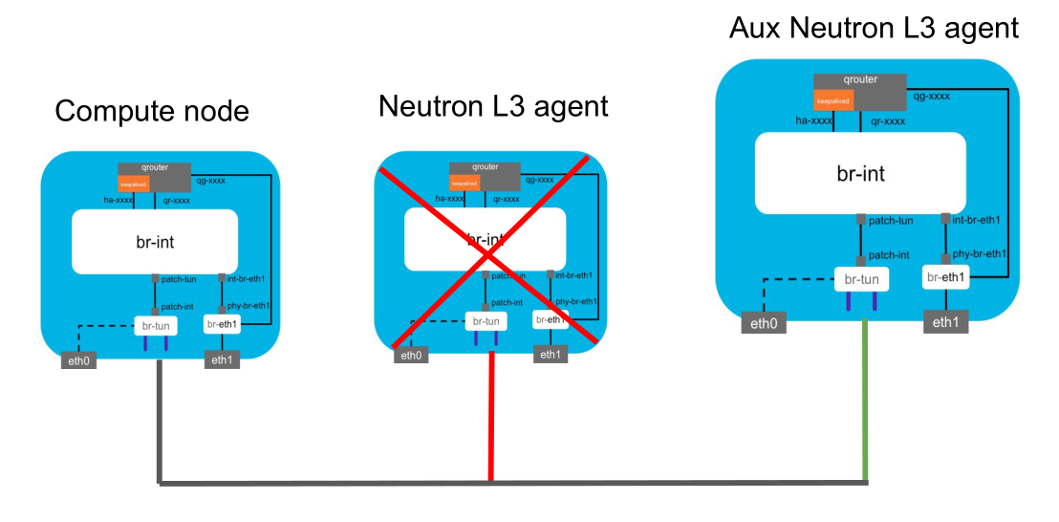
…we forced routers to move to the new agents; this happens in three simple steps:
-
ADD the new L3 agents;
neutron l3-agent-router add|remove agentID routerID -
verify that the agents are registered inside the platform;
neutron agent-list | grep L3 -
For each router force the switch on the new agents (modify the neutron.conf putting l3_max_agents = 2)
ip netns exec $router ip link set dev $interface down; -
Finally remove the old L3 agents from the list
In this way, we can do easily some operations on the controller nodes making sure that nothing could happen during the upgrade/reboot phases, except the stop of the provisioning actions, but our goal was to minimize the downtime for our customers (and doing this the downtime on the upgrade of the controller plane is related to the switch of qrouters (about ~20 pings ) for the first phase and the rollback one.
HOW WE TEST CRITICAL SECTION: DB SCHEMA
As I said before, everything could be ok when the approach is TEST TEST and TEST.
A clear example of this is given by the several issues we found on the update DB schema path and this let
the upgrade playbooks fail for an inconsistency inside the neutron table in which there is the association
between the router and the L3 agents.
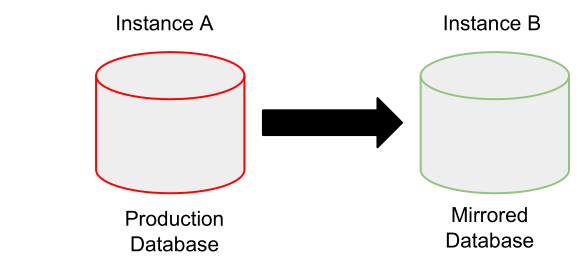
To test this section we performed these steps:
- Dump the entire production openstack db replicating it in the Instance B;
-
Simulate the update launching (for each service) this command using the openstack API:
openstack-db --service "${SERVICE}" --update
UPGRADE COMPUTE NODES: THE TIMELINE
Finally I want to close this post describing the last section of the upgrade in which we had to
evacuate all hypervisors and then update them.
Furthermore, I have to notice that in this hybrid condition, for a little timeframe in which we’ve
had the control plane in Mitaka except Nova and the hypervisors in Kilo, the provisioning and some
operations were locked, so we tried to perform this last section as fast as possible!
In order to upgrade the compute nodes, we prepared a pool of hypervisors with two starting conditions:
- Installed in Liberty (from packages point of view);
- Empty and registered on the platform as nova-compute;
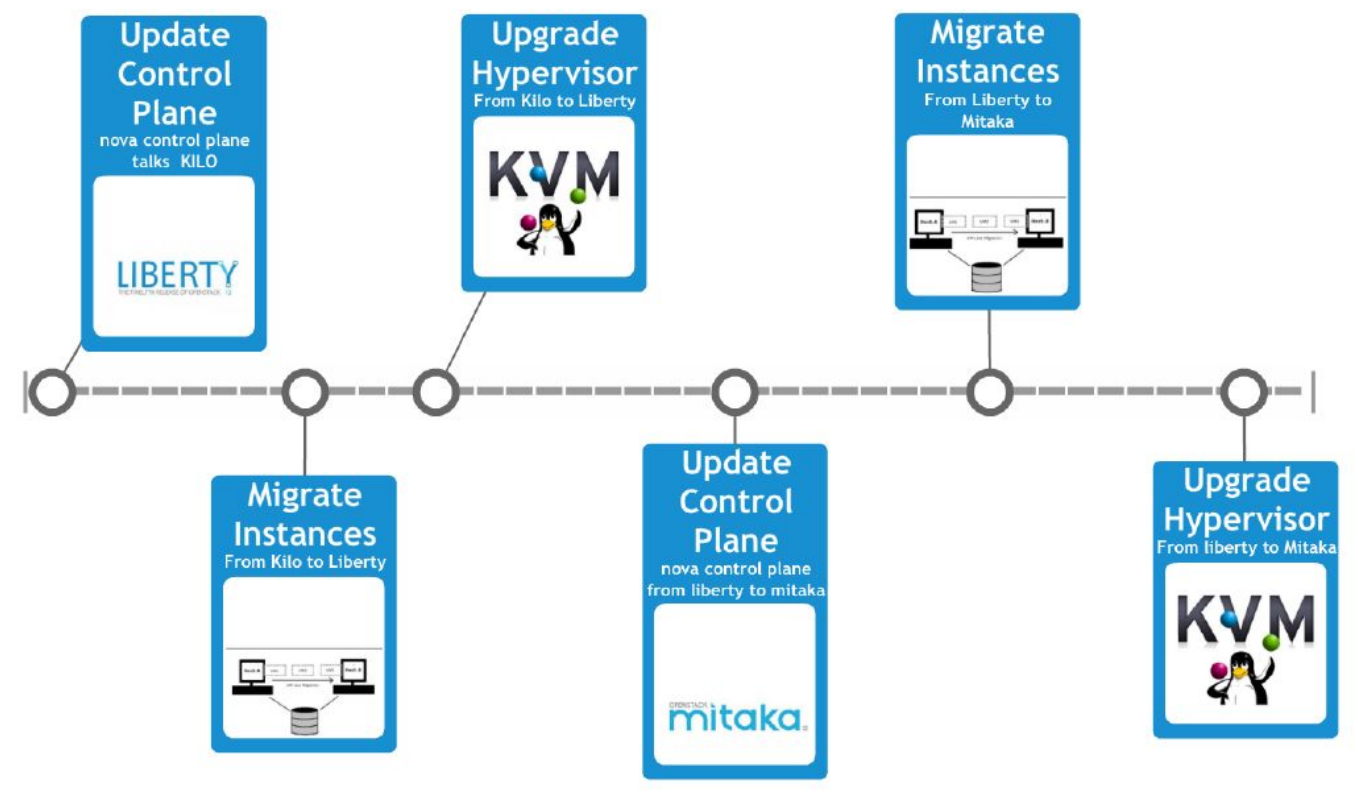
According to the timeline, we update first the nova control plane, then we evacuated the first hypervisor migrating all the instances and since when it was empty we put it in the “candidate-to-upgrade” pool. Once this job it’s done for all the hypervisor, we could upgrade the nova control plane in Mitaka and then redo a second update of all the Hypervisors.
CONCLUSION AND BEST PRACTICES
I just want to close this post related to the talk I’ve done with my team at the Openstack Day Italy with the nice to have list of best practices that could help you to manage the future upgrades of the openstack platform.
- Review the release notes for each release to learn about new, updated and deprecated parameters;
- Have an Openstack mirrored environment (test and dev environments);
- Identify critical update paths (i.e. openstack db schema update);
- Parallelize as much as possible (i.e. packages update);
- Make use of Ansible templates;
- Make your development chain safe making use of CI/CD tools