Building Scalable Distributed Systems - Pt. 3
Proxies and Load balancers are the last piece of this thread. They are the most
important component to make applications able to scale: here we’re not talking about
load in terms of I/O like the previous post, but we’re talking about the management of
the access, the policies to be applied on the applications in order to correctly handle
a great number of requests.
So let’s start from the proxy component.
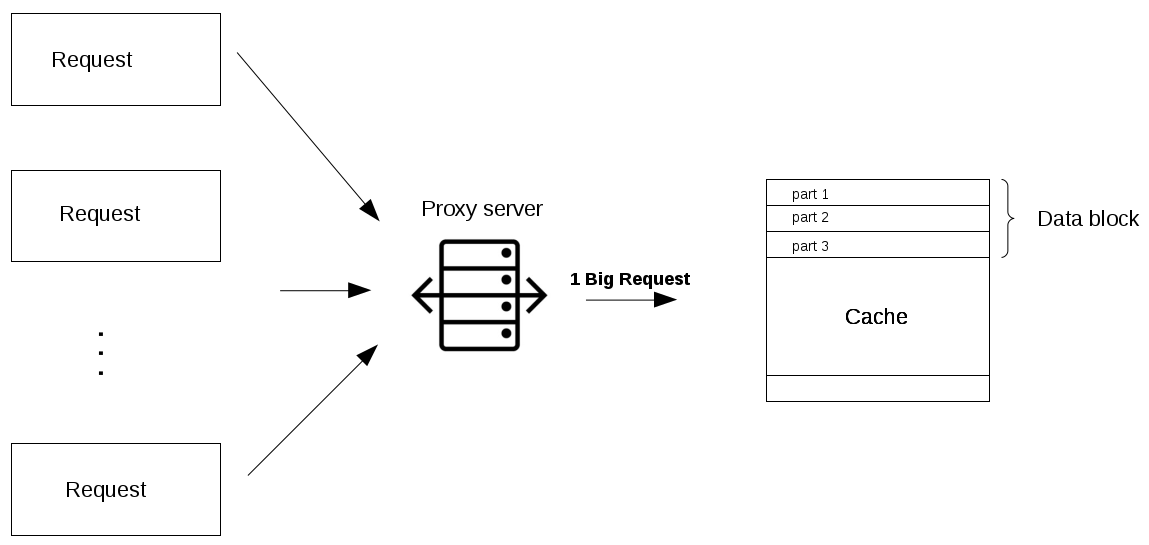
The first thing we need to mention is the collapsed forwarding.
Imagine there is a request for the same data across several nodes, and that piece of
data is not in the cache.
If that request is routed thought the proxy, then all of those requests can be collapsed
into one, which means we only have to read the disk once; this is similar to a cache, but
instead of storing the data/document like a cache, it is optimizing the requests or calls
for those documents and acting as a proxy for those clients.
Another great way to use the proxy is to not just collapse requests for the same data, but
also to collapse requests for data that is spatially close together in the origin store.
The last consideration to do with the proxies is that starting from Nginx as a reverse proxy, there are many options to consider; Squid and Varnish have both been road tested and are widely used in many production Web sites. These proxy solutions offer many optimizations to make the most of client-server communication. Installing one of these as a reverse proxy at the Web server layer can improve Web server performance considerably, reducing the amount of work required to handle incoming client requests.
Finally, now we can go deeply into the last critical piece of every distributed system: we’re talking about load balancers. Their main purpose is to handle a lot of simultaneous connections and route those connections to one of the request nodes, allowing the system to scale to service more requests by just adding nodes. In a distributed system, load balancers are often found at the very front of the system, such that all incoming requests are routed accordingly. In a complex distributed system, it is not uncommon for a request to be routed to multiple load balancers before reach the backend system.
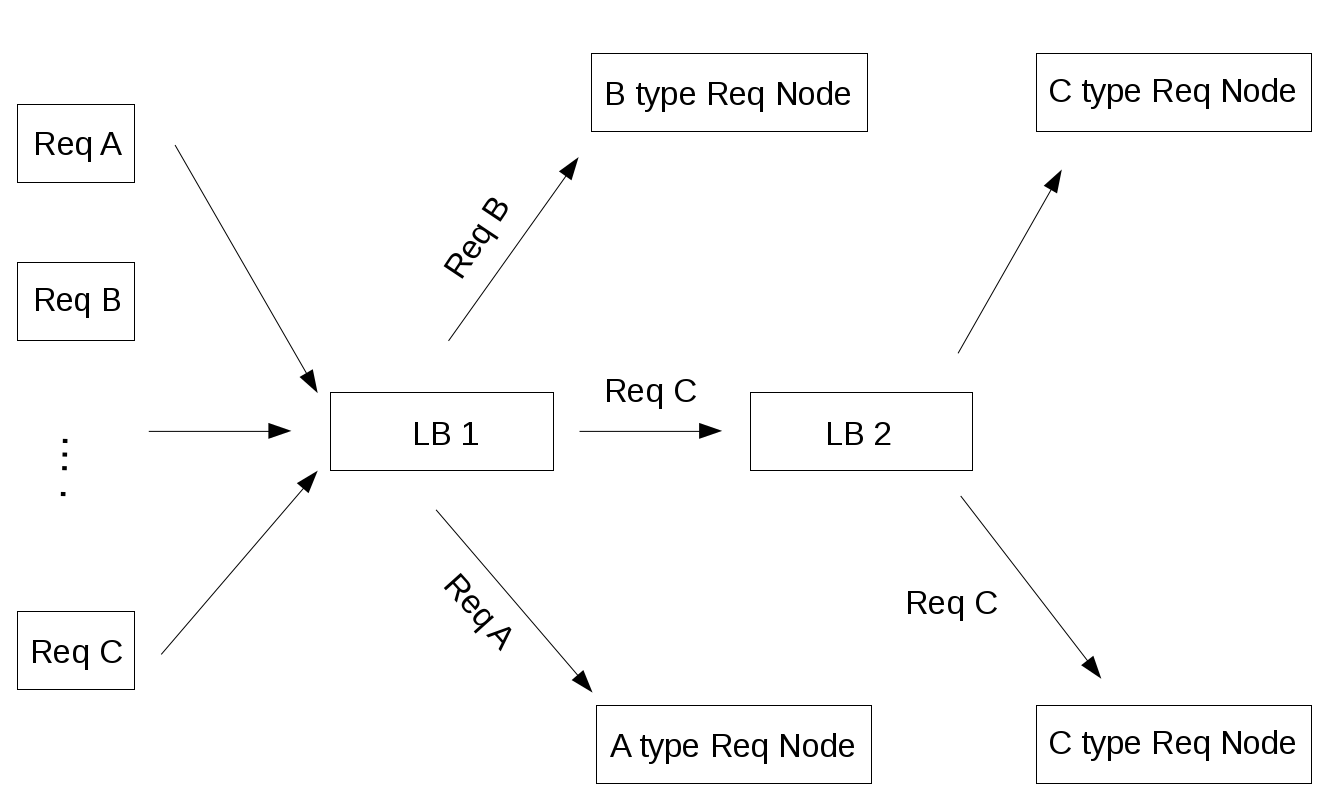
One of the challenges with load balancers is managing user-session-specific data. In an e-commerce
site, for instance, when you only have one client it is very easy to allow users to put
things in their shopping cart and persist those contents between visits.
However, if a user is routed to one node for a session and then a different node on their next visit,
there can be inconsistencies since the new node may be missing that user’s cart contents.
One way around this can be to make sessions sticky so that the user is always routed to the same
node, but then it is very hard to take advantage of some reliability features like automatic
failover.
In larger systems there are all sorts of different scheduling and load-balancing algorithms, including
simple ones like random choice or round robin, and more sophisticated mechanisms that take
things like utilization and capacity into consideration. All of these algorithms allow traffic and
requests to be distributed, and can provide helpful reliability tools like automatic failover, or
automatic removal of a bad node (such as when it becomes unresponsive).
Finally, building scalable distributed systems is a very exciting job… think about every piece
of this puzzle isn’t a simple task because there are lots of variables to play with.
There are N-algorithms, data structures and tools coming to help handle this kind of
architectures and I hope to talk about these stuffs on other posts like this.