Building Scalable Distributed Systems - Pt. 1
Nowadays accessing web resources it’s not static like many years ago. Requirements are changed, users become millions and access a web resource it’s not related just to website consulting or the classic e-commerce pattern: websites have grown, best practice and new principles focusing on architectures have emerged, new requirements that influence the design of large scale architectures are:
-
Availability:The uptime of a website is absolutely critical to the reputation and functionality of many companies. For some of the larger online retail sites (like Amazon, for example), being unavailable for even minutes can result in thousands or millions of dollars in lost revenue, so designing their systems to be constantly available and resilient to failure is both a fundamental business and a technology requirement.
-
Performance: Website performance has become an important consideration for most sites. The speed of a website affects usage and user satisfaction, as well as search engine rankings, a factor that directly correlates to revenue and retention.
-
Reliability: A system needs to be reliable, such that a request for data will consistently return the same data. In the event the data changes or is updated, then that same request should return the new data. Users need to know that if something is written to the system, or stored, it will persist and can be relied on to be in place for future retrieval.
-
Scalability: When it comes to any large distributed system, size is just one aspect of scale that needs to be considered. Just as important is the effort required to increase capacity to handle greater amounts of load, commonly referred to as the scalability of the system. Scalability can refer to many different parameters of the system: how much additional traffic can it handle, how easy is it to add more storage capacity, or even how many more transactions can be processed.
-
Manageability: Designing a system that is easy to operate is another important consideration. The manageability of the system equates to the scalability of operations: maintenance and updates. Things to consider for manageability are the ease of diagnosing and understanding problems when they occur, ease of making updates or modifications, and how simple the system is to operate. (I.e., does it routinely operate without failure or exceptions?)
-
Cost: Cost is an important factor. This obviously can include hardware and software costs, but it is also important to consider other facets needed to deploy and maintain the system. The amount of developer time the system takes to build, the amount of operational effort required to run the system, and even the amount of training required should all be considered.
Each of these principles provides the basis for decisions in designing a distributed architecture and one important thing is to consider to achieve a good trade off among these features we would like to provide, for instance, choosing to address capacity by simply adding more servers (scalability) can come at the price of manageability (you have to operate an additional server) and cost (the price of the servers).
This discussion is focused on some of the core factors that are central to almost all large Web applications: we are talking about services, redundancy, partitions, and handling failure. Each of these factors involves choices and compromises, particularly in the context of the principles described previously. In order to explain these in detail it is best to start with an example.
The Basics
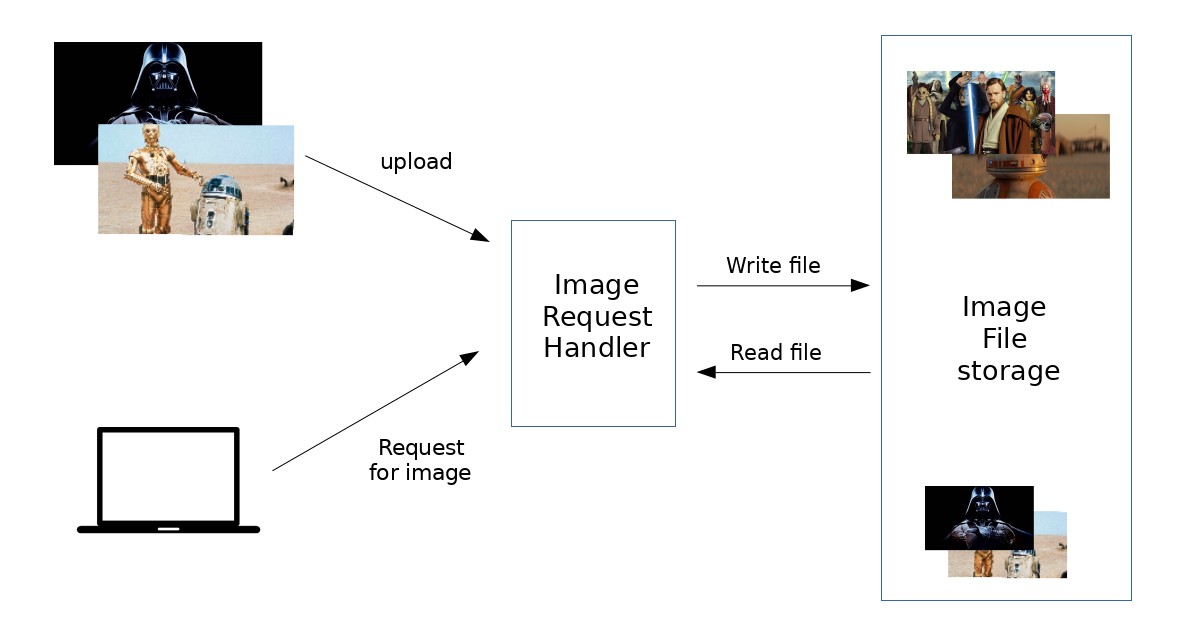
Let’s take as example an image hosting application like Flickr: it is a good example of an application that would take care about all the aspects described above.
For big sites that host and deliver lots of images, there are challenges in building an architecture that is cost-effective, highly available, and has low latency (fast retrieval). There is also the need to understand how to manage a great flow of data to keep images with the right level of quality, to retrieve data in an efficient manner, trading off the costs for that kind of operations and the manageability of the system.
For a better explanation, let’s assume that this application has two key parts: the ability to upload (write) an image to the server, and the ability to query for an image. While we certainly want the upload to be efficient, we care most about having very fast delivery when someone requests an image, so we can say we have these constraints:
- There is no limit to the number of images that will be stored, so storage scalability, in terms of image count needs to be considered
- There needs to be low latency for image requests
- Take care of data reliability
- The system should be easy to maintain (manageability)
- There is the need to design a cost-effective system
In the next section (published as soon as possible), we are going to discuss the basic building blocks to design scalable distributed systems, how to build services, how to make them redundant, partitioning them in a microservices fashion and starting from basic operating systems concepts we’ll try to make some considerations about the most important techniques and algorithms.